> _
Implementation of the Vision Transformer Architecture in PyTorch
2024
View on GitHubAn Implementation of the paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale in PyTorch.
Abstract
Since their introduction, Vision Transformers have taken a significant role in today’s field of deep learning. Researchers have started to integrate the proposed vision capabilities into large language models (LLMs), which are based on the Transformer architecture introduced by Vaswani et al. In this project the architecture and the concepts behind the proposed Vision Transformer architecture were explored and subsequently implemented. Since the proposed model is rather new, only few reference implementations exist and there are currently no programming libraries offering “ready-to-use” modules. Therefore, in this project the model was implemented “from scratch” in PyTorch and evaluated on a simple image classification task using the common CIFAR-10 dataset.
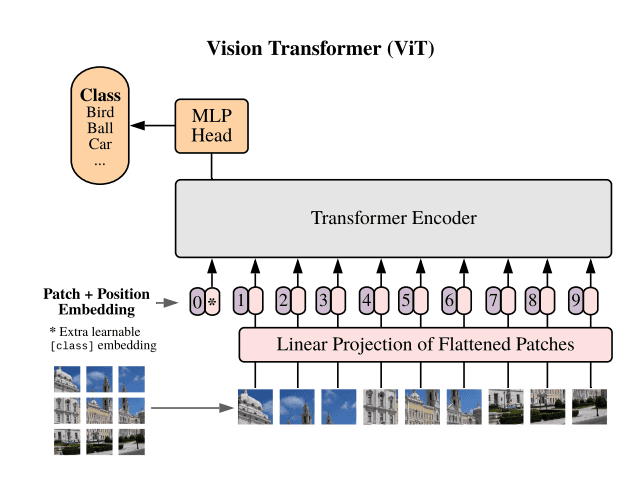
The Vision Transformer architecture introduced by Dosovitskiy et al.